You can use the Edit Trace window to define the source for the X-Axis and set any algorithms, offsets etc.
To define the X-Axis settings:
- Display the X-Y Plot in Design mode (see Display an X-Y Plot in Design Mode).
- Right-click just to the right of the Y-Axis or just above the X-Axis.
A context-sensitive menu is displayed. - Select the Edit Trace Settings option.
The Edit Trace window is displayed. - Use the X-Axis section of the Edit Trace window to define the X-Axis settings:
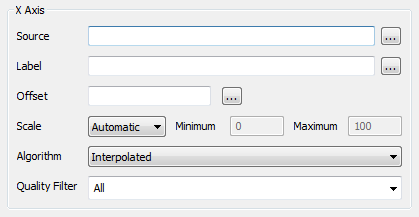
- Source—Define the data source that is used to determine the values that are represented by the X-Axis. You can either enter the location of the data source as a tag or you can select the data source from a list by using the browse button. The X-Axis will represent the range of values for the selected data source and the X component of the marker value will be a value from the selected data source.
For example, if you select an analog point named ‘Flow Monitor 1’ as the data source, the X-Axis will represent the range of possible values for the point (as long as the X-Axis uses Range scaling). The full range of values is defined in the Alarm Limits section of the point's form. The labels used on point forms for the range fields vary between drivers. For example, Zero Scale to Full Scale or Underrange to Overrange.
NOTE: The Alarm Limits can appear as a grouping on the point form or as a separate tab, depending on the driver. For more information about a driver’s Alarm Limits, see the documentation for the relevant driver.
The X component of each marker would be a value from the ‘Flow Monitor 1’ point (the value at the specific time shown on the Time Line).
- Label—Define the text string that represents the trace in the key. The Label entry is an expression and is the full name property of the Source (by default). You can change the Label as required.
For more information on expressions, see Welcome to the Guide to Expressions in the ClearSCADA Guide to Expressions.
- Offset—Define a time offset for the X-Axis (as required). When used, the offset sets ViewX to plot values from a specified amount of time in the past or future against the X-Axis. This is useful when you need to use the X-Y Plot to examine the relationship between the values of different sources at different times.
For example, if you want to examine the values on an X-Y Plot at 11:50 and the X-Axis offset is set to -10M (10 minutes in the past), the values that are plotted on the X-Axis for 11:50 are actually the values that were reported for the source point at 11:40. So, if there is no offset on the Y-Axis, the marker values for 11:50 will be:
- X component = The value of the X-Axis source at 11:40 (ten minutes prior to the time at which the value is plotted on the X-Y Plot)
- Y component = The value of the Y-Axis source at 11:50 (the value at the time it is plotted on the X-Y Plot).
- Scale—Choose the method of scaling that will be used by the X-Axis. The method of scaling affects how the Y-Axis calculates the range of values that it represents.
Choose from:
- Manual—You define the lowest value and highest value that can be shown on the X-Axis. You can define the values in the Minimum and Maximum fields in the Scale section.
- Range—Scales the X-Axis according to the point's full range of values. The full range is defined in the Alarm Limits section of the point's form. The labels used on point forms for the range fields vary between drivers. For example, Zero Scale to Full Scale or Underrange to Overrange.
NOTE: The Alarm Limits can appear as a grouping on the point form or as a separate tab, depending on the driver. For more information about a driver’s Alarm Limits, see the documentation for the relevant driver.
- This only applies to analog points.
- Automatic—Scales the X-Axis automatically so that it can display the lowest and highest values that are on display within suitable limits. This means that the X-Axis is updated so that the lowest and highest values can be shown.
- Algorithm—You have to choose the calculation that is to be used to provide the values for the X-Axis’s source data. The result of the calculation is plotted on the X-Y Plot instead of the actual value that was reported for the source. This is useful when you need to monitor calculated values, such as average values.
The algorithm calculation is performed at a regular interval (which is defined by the Resample Interval). The time period between each resample interval is referred to as the calculation period. The algorithm calculation is performed on the values recorded during the calculation period.
The Resample Interval is calculated by dividing the total time of the time axis by the number of Data Points configured.

Example:
If the Duration is set to 1H and the number of Data Points is set to 4, then the Resample Interval is 15M.
If the algorithm is set to Average and the Resample Interval is 15M, the average value for the X-Axis’s source will be calculated every 15 minutes using the values that were reported during the previous 15 minutes.
You can choose from any of the following algorithms:
- 1hAverage—The average value over an 1 hour period that starts at the beginning of the calculation period (defined by the resample interval).
- 8hAverage—The average value over an 8 hour period that starts at the beginning of the calculation period (defined by the resample interval).
- 24hAverage—The average value over an 24 hour period that starts at the beginning of the calculation period (defined by the resample interval).
- Average—The mean average of the data for the calculation period (defined by the resample interval).
- Average Interpolated—This is a calculation to estimate a value that is not included in the data for the calculation period (defined by the resample interval). The calculation uses the average value in the calculation period to define the estimated value.
- Average Last—The average value or the last good average value (if there are no values in the calculation period that is defined by the resample interval).
- Count—The number of raw values in the data for the calculation period (defined by the resample interval).
- Delta—The difference between the first value and the last value in the raw data for the calculation period (defined by the resample interval).
- DurBad—The duration (in seconds) of values marked as bad quality in the raw data for the calculation period (defined by the resample interval).
- DurGood—The duration (in seconds) of values marked as good quality in the raw data for the calculation period (defined by the resample interval).
- End—The last value in the data for the calculation period (defined by the resample interval). The timestamp is the time at the end of the sample, which may not correspond with the time at which the last value was reported.
- Interpolated—This is a calculation to estimate a value that is not included in the data for the calculation period (defined by the resample interval).
- Max—The highest value in the data for the calculation period (defined by the resample interval).
- Max Interpolated—This is a calculation to estimate a value that is not included in the data for the calculation period (defined by the resample interval). The calculation uses the maximum value in the calculation period to define the estimated value.
- Max Last—The maximum value or the last good maximum value (if there are no values in the calculation period that is defined by the resample interval).
- MaxTime—The highest value in the data for the calculation period (defined by the resample interval) and the time at which it was reported.
- Min—The lowest value in the data for the calculation period (defined by the resample interval).
- Min Interpolated—This is a calculation to estimate a value that is not included in the data for the calculation period (defined by the resample interval). The calculation uses the minimum value in the calculation period to define the estimated value.
- Min Last—The maximum value or the last good minimum value (if there are no values in the calculation period that is defined by the resample interval).
- MinTime—The lowest value in the data for the calculation period (defined by the resample interval) and the time at which it was reported.
- PerBad—The percentage of values marked as bad quality in the data for the calculation period (defined by the resample interval). (1=100%).
- PerGood—The percentage of values marked as good quality in the data for the calculation period (defined by the resample interval). (1=100%).
- Range—The difference between the maximum value and the minimum value in the data for the calculation period (defined by the resample interval).
- Start—The first value in the data for the calculation period (defined by the resample interval). The timestamp is the time at the beginning of the sample, which may not correspond with the time at which the first value was reported.
- StdDev—The standard deviation of the data for the calculation period (defined by the resample interval). Standard deviation is a commonly used measure of spread by statisticians. It allows the percentile rank to be calculated for any value in the data. You will need an understanding of statistics to make use of the information provided by this algorithm.
- Sum—The total of the data for the calculation period (defined by the resample interval).
- Time Average—The time-weighted average value for the calculation period (defined by the resample interval). The time-weighted average differs to the average algorithm as it takes into account the amount of time that the source remains at each value in the calculation period.
- Total—The totalized value (time integral) of the data for the calculation period (defined by the resample interval).
- Variance—The spread of the values in the data for the calculation period (defined by the resample interval). Like StdDev, Variance is used to measure the extent of the spread of values in the data, and you need an understanding of statistics to make use of the information provided by this algorithm.
- Quality Filter—Use this combo box to specify the quality of the values that you want to use for the X component of the X-Y plot.
A value's quality provides an indication of its reliability. The possible quality types are:
- Good quality (values that are reliably accurate)
- Bad quality (values that are unreliable and may be inaccurate)
- Uncertain quality (values with uncertain quality because, for example, communication with the monitoring device was unsuccessful)
- All qualities.
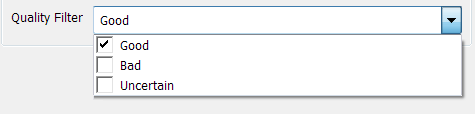
Use the Quality Filter property to exclude values of a certain quality type. For example, you might want the plot to show Good (that is, reliable) values only. In this situation, you would select the Good tick box and clear the other tick boxes, as follows:
- Source—Define the data source that is used to determine the values that are represented by the X-Axis. You can either enter the location of the data source as a tag or you can select the data source from a list by using the browse button. The X-Axis will represent the range of values for the selected data source and the X component of the marker value will be a value from the selected data source.
Further Information
Resample Interval: see Specify how Often Historic Data is Calculated in the ClearSCADA Guide to Core Configuration.
Data quality: see Quality in the ClearSCADA Guide to Drivers.